Azure Purview Integration with Azure Databricks
In this article, I will provide my experience on working with Purview and Databricks integration. I will discuss the steps here.
Prerequisites:
- For registering and scanning of assets, we need to have data source administrator access
- For scanning from Azure Storage Account, purview managed identity should have Storage Blob Data Reader access
Steps:
- First understand the data landscape and accordingly build the collection hierarchy. Take a note of all the data sources and different zones like landing, bronze, silver etc.
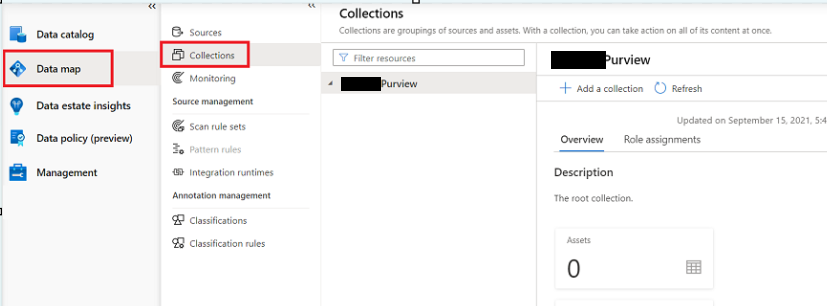
2. Once we are done with building the collection hierarchy, register the data sources at the respective hierarchies.
3. Registering & Scanning of ADLS Gen 2 is very simple in Purview. Just the basic access of Purview Managed Identity in ADLS Gen 2 as Storage blob reader access is sufficient.
4. Now the main discussion is how do we integrate this with Azure Databricks. First we must understand whether it is default Hive Metastore or Unity Catalog
5. If it’s Hive Metastore, then the pre-requistes would be to get a SHIR installed on VM. And the VM should have Java Run Time 11 installed. Please note higher version will have incompatibility issues.
6. Go to Data bricks and generate a token.
7. Go to Azure Key Vault, create a secret by providing the generated token from Azure Data bricks. Ensure that Purview Managed identity is given Key Vault Secret User access before scanning.
8. Go to Purview Portal and create new credential using the created key vault from above steps.
9. Then create a cluster and keep the cluster running during scan.
10. Below is the snapshot of configuration while scanning Hive Metastore.
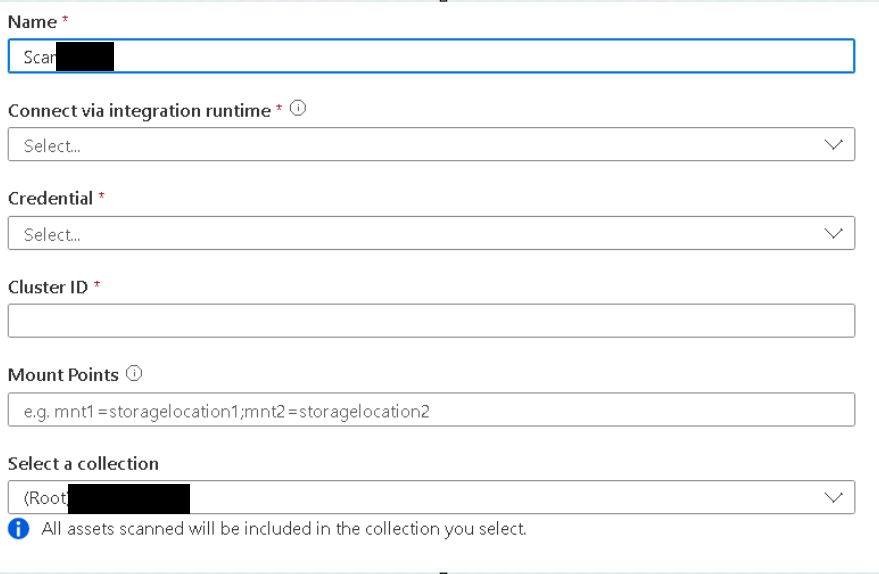
11. If it is Unity Catalog, there is no need of self hosted integrated run time. And no need of cluster to run. We just need to provide the key vault credential and Http path of sql datawarehouse
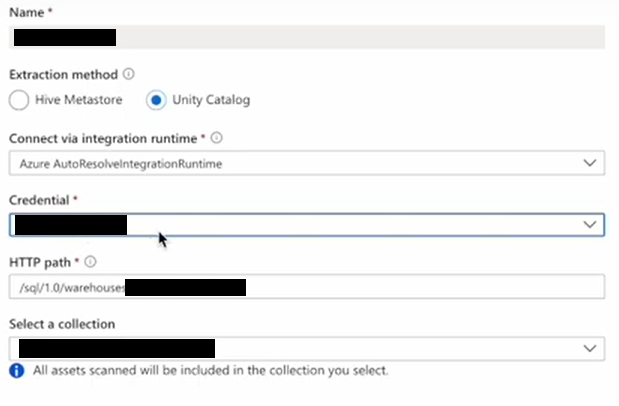
Now here are the main differences between Hive Metastore and Unity Catalog. When it is integrated with default metastore, solution is somewhat better integrated than Unity Catalog, so it captures the minimal lineage which is just capturing the asset relationship. It does not show lineage from data processing systems through notebooks. This is a great article that shows the detailed step on Purview integration with Hive Metastore https://erwindekreuk.com/2023/01/connect-azure-databricks-to-microsoft-purview/
For Hive metastore, to show the lineage details of notebook execution one needs to use generic spark lineage connector. It has predefined scripts to help with lineage creation.
https://github.com/microsoft/Purview-ADB-Lineage-Solution-Accelerator
For Unity Catalog, it is little bit complicated as there is no official integration documentation from Microsoft. This is the best resource available in the internet. Thanks to Barny Self for explaining this in so detail.
https://www.youtube.com/watch?v=Ae1goH1xOCY
It utilizes the PyApache Atlas API of Purview. Basically it imports the entities, processes, relationship definition from unity catalog and create these exact definitions and uploads it into Purview. The lineage that shows on Databricks Unity catalog is replicated on Purview.
Here are the Microsoft references on Purview Integration with Databricks.
https://learn.microsoft.com/en-us/purview/register-scan-azure-databricks
https://learn.microsoft.com/en-us/purview/register-scan-azure-databricks-unity-catalog
{kind=link}